Architecture¶
This section provides a detailed overview of the AgentHeaven architecture, including its core components and their interactions. It also introduces the Unified Knowledge Format (UKF) and the Imitator component for lifelong learning.
1. System Architecture¶
AgentHeaven is a framework designed to build domain-specific applications by treating knowledge as a core asset. Its architecture is built around the concept of a Unified Knowledge Format (UKF), which ensures that all forms of knowledge — from documents and database schemas to user queries and function results — are managed in a consistent way. This approach creates a seamless pipeline where knowledge can be easily extracted, stored, and utilized by agents to perform tasks.
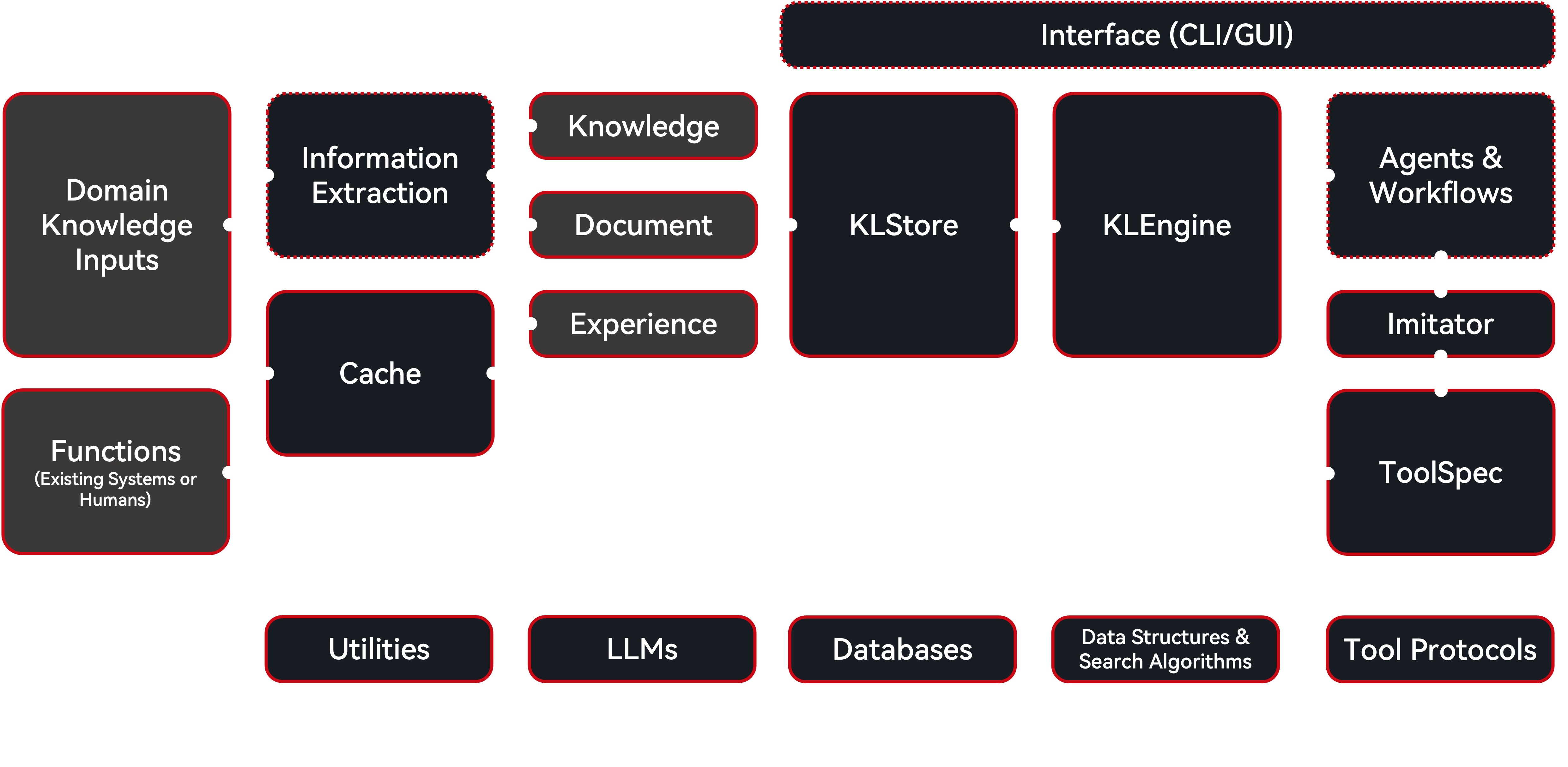
AgentHeaven System Architecture¶
Specifically, AgentHeaven is built on several components that work together to create a flexible, intelligent system:
Cache: A component for monitoring that accumulates and temporarily stores function calls and their results. It can be used for logging historical user queries, annotations, LLM inputs/outputs, agent trajectories, or for collecting data from a running system for lifelong learning.
LLM: AgentHeaven uses LiteLLM to provide a unified interface for various LLMs. The LLMs are an integral part of the AgentHeaven implementation, with configurable presets, rather than just a service.
Prompts: Prompts are managed as Jinja + Babel templates that are also convertible to UKF. This provides a unified interface for prompt engineering and versioning, treating prompts as a form of knowledge.
Database: AgentHeaven specializes in data-related applications and puts considerable effort into optimizing database interactions. It integrates SQLAlchemy to connect to various databases, efficiently storing and retrieving UKF data.
Vector Database: For applications requiring semantic search capabilities, AgentHeaven integrates with vector databases through LlamaIndex. This allows for efficient storage and retrieval of high-dimensional vector representations of knowledge.
BaseUKF: The UKF protocol is designed to separate the extraction, storage, management, retrieval, and utilization of knowledge. As a semantic layer, BaseUKF unifies all components required in agentic workflows as data.
KLStore: The storage layer for long-term management of UKFs. It supports a variety of solutions, including in-memory, file systems, databases, remote storage, cascading, and routing.
KLEngine: The utilization layer for UKFs. For example, retrieval-based utilization can leverage knowledge stored in UKFs to answer queries or perform tasks using methods like string matching, faceted search, vector search, or graph walks. Another example is using the knowledge for model fine-tuning and knowledge distillation.
KLBase: The core of AgentHeaven, which integrates one or multiple KLStore and KLEngine instances. It provides a utilization interface for any agentic workflows built on top of it, abstracting away the underlying implementation details.
ToolSpec: A structured representation of tools (functions, APIs, etc.). Centered around FastMCP 2.0, ToolSpec allows conversion from function, code, MCP or FastMCP Tools, and converts to function, signature, code, MCP or FastMCP Tools, Function call JSON Schema, string, and UKF.
Imitator: An agent builder based on imitation learning. It creates and continuously refines domain-specific agents through weak supervision, using the knowledge stored in the KLBase.
2. Unified Knowledge Format (UKF) Architecture¶
Unified Knowledge Format (UKF) is a core concept in AgentHeaven, providing a standardized way to represent and manage knowledge across different domains and applications. The UKF architecture is designed to be extensible and adaptable, allowing users to define domain-specific knowledge representations while maintaining a consistent interface for knowledge operations.
Unified Knowledge Format (UKF) Architecture¶
To develop domain-specific applications, domain-specific UKF Variants should first be created under the guidance of domain experts. For example, in a database scenario, enums, columns, tables, and database schemas are important types of knowledge, so each should be defined as a UKF Variant.
For convenience, AgentHeaven provides some basic level-1 variants (KnowledgeUKFT, ExperienceUKFT, DocumentUKFT, etc.), certain built-in level-2 variants (for databases, etc.) that inherit from level-1 variants, and allows users to define their own level-2 or level-3 variants by inheriting from built-in variants or other user-defined variants.
Then, all domain knowledge can be converted to UKF instances of these variants, which support all operations as defined in the BaseUKF protocol.
The underlying handling of BaseUKF should be imperceptible to end users and application developers, who only need to focus on the high-level operations of UKF instances.
For contributors, since BaseUKF uses a type-based adapter system, they can easily implement adapters to modify the BaseUKF definition or link UKF to their own backends.
Specifically, each field in the BaseUKF schema is associated with a UKF Type. To connect BaseUKF to a custom backend, contributors need to implement adapters for the UKF Types—for example, mapping
UKFShortTextTypetoVARCHAR(255)in SQL databases, or linkingUKFVectorTypeto_vecin vector databases.For built-in adapters, AgentHeaven aims to provide a unified implementation instead of separate adapters for each backend. Therefore, we introduce another Connector layer, which uses third-party integrators to connect to various backends. For example, the SQLAlchemy connector connects to various SQL databases, and the LlamaIndex connector connects to various vector databases.
As for the conversion from raw domain knowledge to UKF instances—a highly domain-specific process—AgentHeaven recommends Agents for Agents: we are building the knowledge base for agents, while using agents to help us build it. Specifically, in the next section, we will introduce the Imitator component, which we believe to be a general mechanism for lifelong learning in agentic systems. In our demos, we show how to use Imitators and AgentHeaven utils to quickly build a UKF extractor agent in practical scenarios.
3. Imitator Architecture¶
Conceptually, we formulate all tasks intended to be solved via an agentic workflow as a Function. Currently, AgentHeaven only considers functions that are both record-wise (meaning each input record corresponds to exactly one output record) and deterministic. Notice that these conceptual functions are not necessarily limited to actual functions implemented in code but also include human annotations, LLM calls, or agentic workflows.
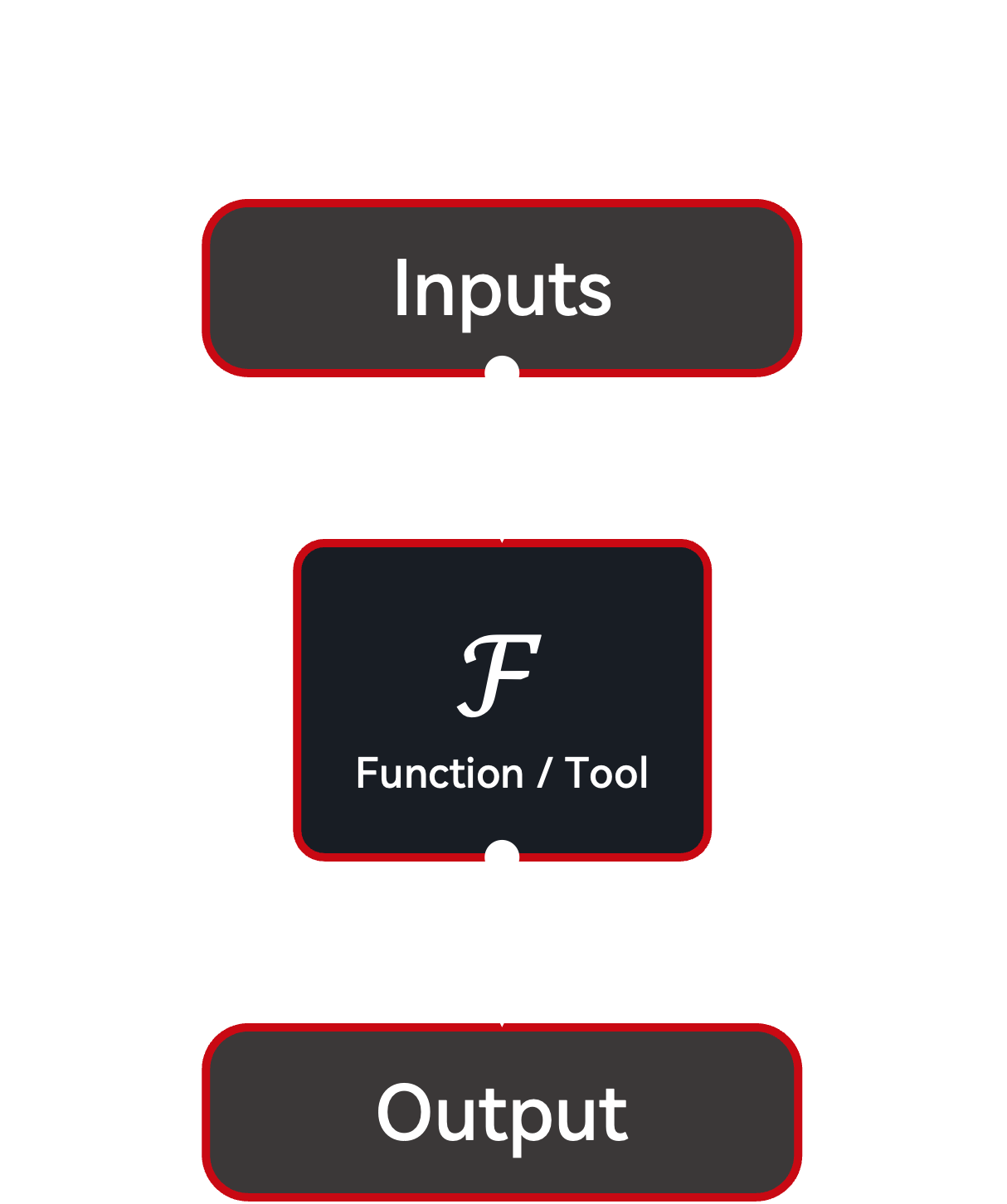
Imitator Architecture: Function¶
To enable lifelong learning, we first need to keep track of function calls and their results. This is handled by the Cache component (specifically, the CallbackCache), which can be used as a decorator to wrap any function, creating a Monitored Function. While the monitored function continues to receive the same inputs and produce the same outputs, it also emits CacheEntry instances to the Cache, which records the function name, input arguments, output results, timestamp, and other metadata. These CacheEntry instances can then be transformed into UKF instances (e.g., ExperienceUKFT) and stored in the KLBase for long-term management.
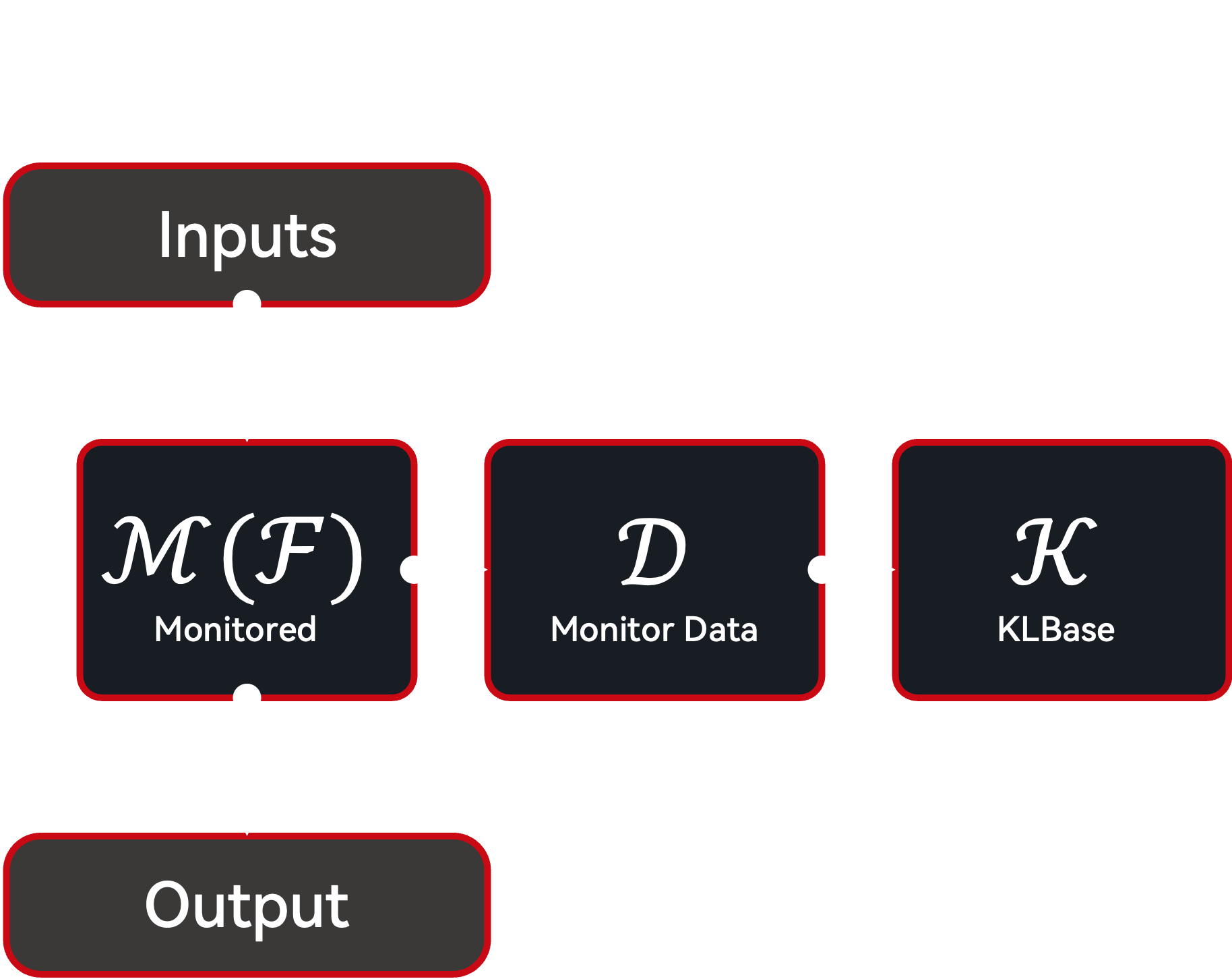
Imitator Architecture: Monitored Function¶
Now, we have a KLBase that contains function experiences and, potentially, other knowledge as well. The next step is to build a Mimic Function from the KLBase. A mimic function is a black box that emulates the original function. It takes the same inputs, along with the KLBase, to produce outputs that are similar to (or even better than) those of the original.
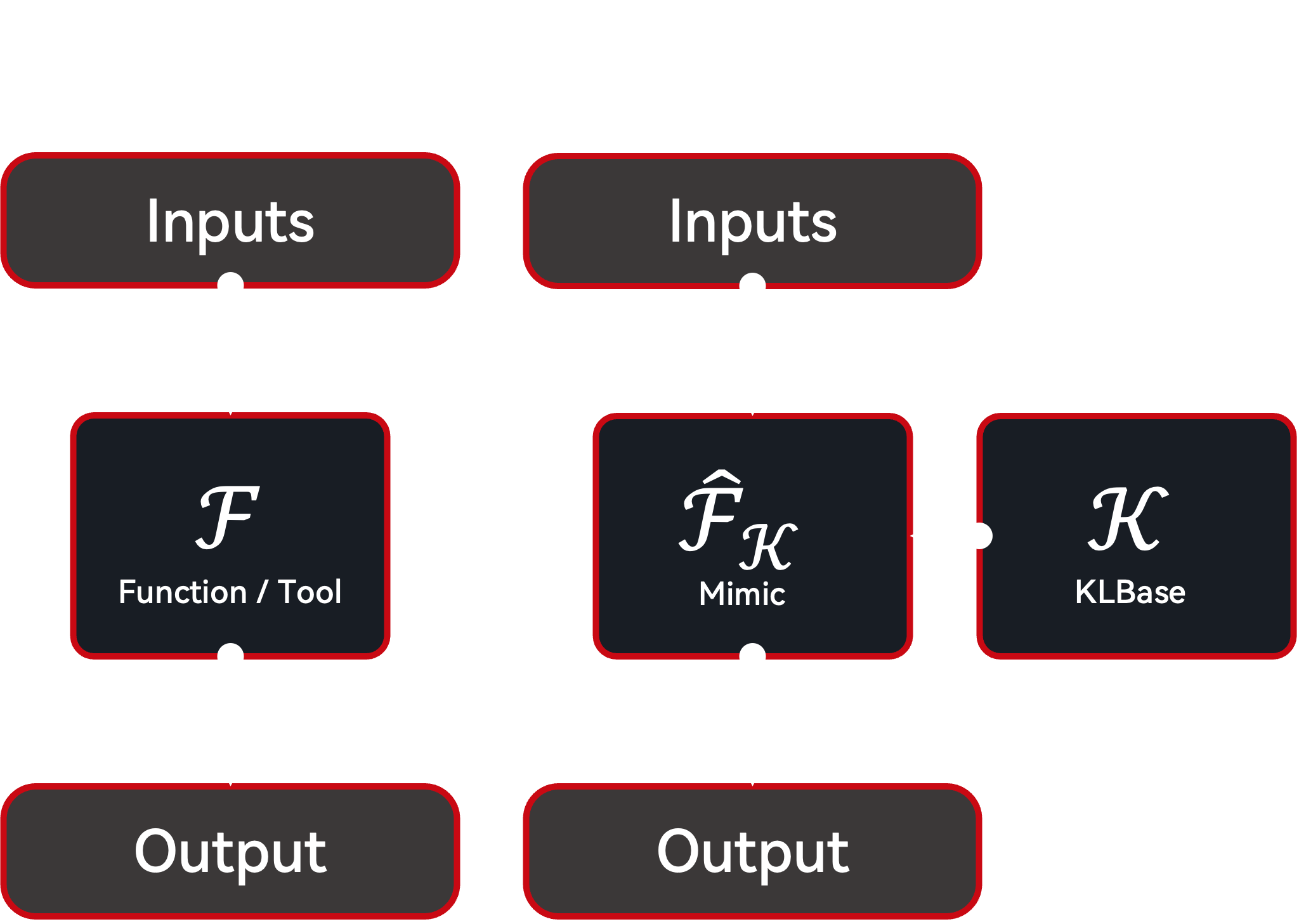
Imitator Architecture: Mimic¶
The mimic function can be implemented in various ways, such as In-Context Learning (ICL) with prompt engineering, fine-tuning, code generation with ExperienceUKFT as unit tests, or exact/fuzzy matching with historical inputs/outputs. This mimic function can then be used as a drop-in replacement for the original function.
Finally, we can assemble the Function, Monitor (Cache), and mimic function (or a mimic function factory) to create an Imitator. The imitator is tied to a KLBase and can be asked to monitor any function, quietly collecting experiences in the background and storing them in the KLBase.
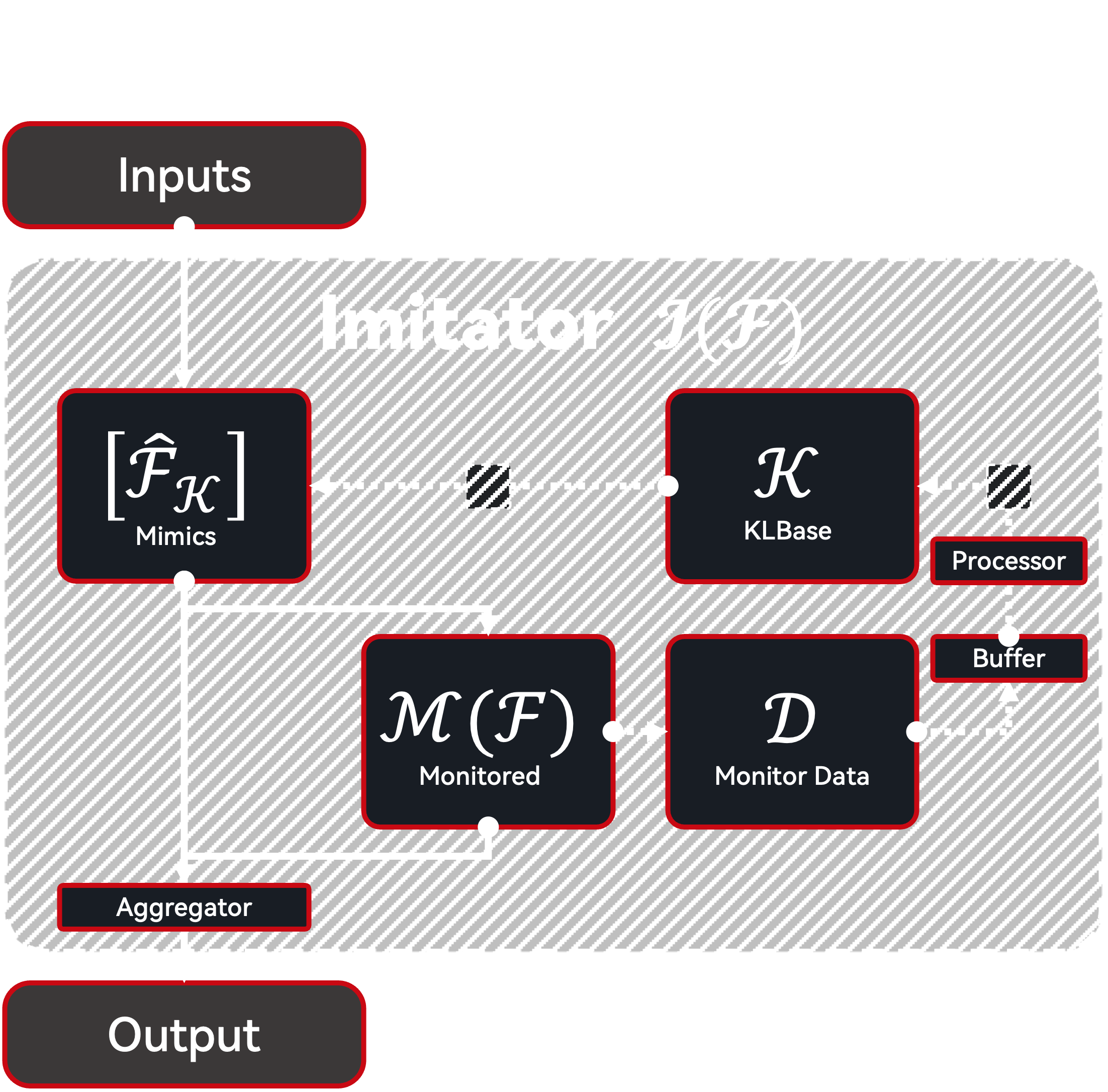
Imitator Architecture: Full Imitator Workflow¶
At any time, the imitator can be asked to create a mimic function from the KLBase. An Aggregator can then be applied to combine the outputs of the original function and different versions of the mimic function to produce the final output.
Eventually, the aggregated mimic functions can completely replace the original function, either by producing better outputs (due to the introduction of extra knowledge from the KLBase or learning from historical data) or by producing outputs at a lower cost (e.g., replacing human annotation with an LLM-based mimic function, or even faster, a fixed code snippet from a codegen-based mimic function).
AgentHeaven currently supports only one built-in Imitator, which uses a cascading system as the aggregator: a series of ordered mimic functions are tried sequentially, and the first non-empty output is returned as the final result. The mimic function is implemented with ICL, which constructs a prompt with historical experiences retrieved from the KLBase as in-context examples.
Other aggregator and mimic function implementations will be provided in the future, so stay tuned.
For developers, you can inherit the base Imitator class to implement your own Imitators with custom Monitor, Mimic, and Aggregator components.
Notice that in the above architecture diagram, there are small shadowed boxes between the components, involving the process of processing monitored data in buffer and utilizing the KLBase to create mimic functions. These processes require domain-specific logic, which may require human developer. Yet, the Agents for Agents approach can be applied here, as those boxes can be abstracted as Functions, which can recursively be implemented via an Imitator.
Intuitively, for any tasks that can benefit from automation, there will always be commonness and differences. The commonness (80% of easy cases) can be handled by the Imitator, while the differences (20% of hard cases) must be handled with human intervention. Yet, if the intervention is costly, it must also be a task that can benefit from automation, which again have commonness and differences. By recursively applying this principle, we progressively automate more and more tasks, keeping human-in-the-loop while minimizing human effort. Just like self-attention as the building block of transformers, we believe the Imitator is the building block of lifelong learning in agentic systems.