架构¶
本节将详细介绍 AgentHeaven 的架构,包括其核心组件及交互关系。它还介绍了统一知识格式(UKF)与用于终身学习的模仿器(Imitator)组件。
1. 系统架构¶
AgentHeaven 是一个面向构建 垂直领域应用 的框架,其核心是把知识视为核心资产。其架构围绕 统一知识格式(UKF) 的概念构建,确保所有形式的知识——从文档与数据库模式到用户查询和函数结果——都以一致的方式管理。这种方法打造了一条无缝的流水线,使智能体能够轻松地提取、存储并利用知识来执行任务。
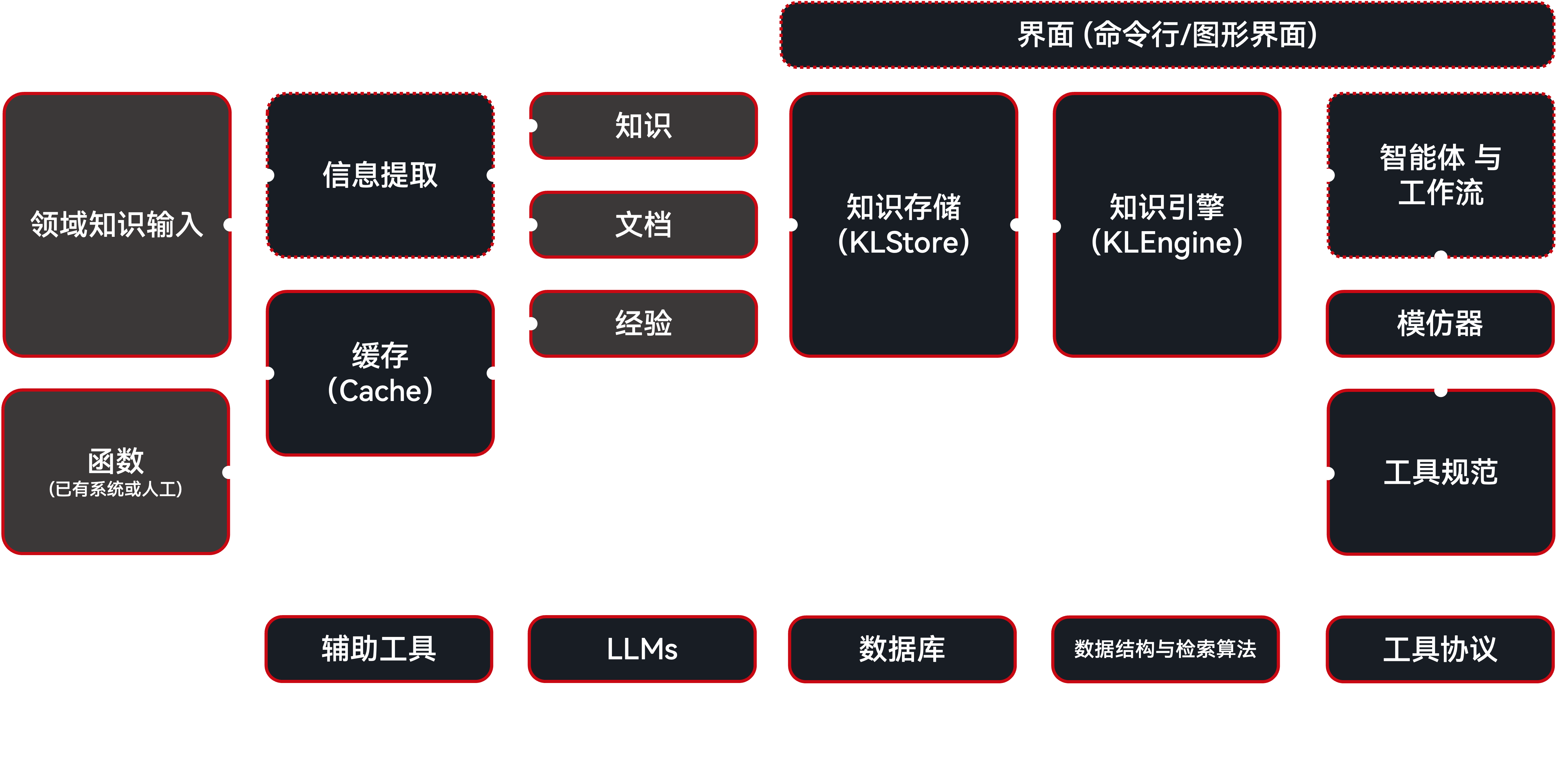
AgentHeaven 系统架构¶
具体而言,AgentHeaven 由若干组件协同工作,以构建一个灵活而智能的系统:
Cache(缓存):用于监控、累积并临时存储函数调用及其结果。可用于记录历史用户查询、标注、LLM 输入/输出、智能体轨迹,或从在线系统收集数据以支持终身学习。
LLM(大语言模型):AgentHeaven 使用 LiteLLM 为多种 LLM 提供统一接口。LLM 是 AgentHeaven 实现中不可或缺的一部分,支持可配置的预设,而不仅仅是一个外部服务。
Prompts(提示词):提示词以 Jinja + Babel 模板管理,并可转换为 UKF。这为提示工程与版本管理提供统一接口,将提示词视作一种知识。
Database(数据库):AgentHeaven 专注数据相关应用,并在优化数据库交互方面投入大量精力。集成了 SQLAlchemy 以连接多种数据库,高效存取 UKF 数据。
Vector Database(向量数据库):对于需要语义检索的应用,AgentHeaven 通过 LlamaIndex 集成向量数据库,以高效存储与检索知识的高维向量表示。
BaseUKF:UKF 协议旨在分离知识的提取、存储、管理、检索与利用。作为语义层,BaseUKF 将智能体工作流所需的各类组件统一为数据。
KLStore(知识存储):用于 UKF 的长期管理与持久化的存储层。支持多种方案,包括内存、文件系统、数据库、远程存储、级联与路由等。
KLEngine(知识引擎):UKF 的利用层。例如,基于检索的利用可借助 UKF 中存储的知识,通过字符串匹配、分面检索、向量检索或图遍历等方法回答查询或执行任务;又如,利用这些知识进行模型微调与知识蒸馏。
KLBase(知识库):AgentHeaven 的核心,整合一个或多个 KLStore 与 KLEngine 实例。它为其上层的任意智能体工作流提供统一的利用接口,屏蔽底层实现细节。
ToolSpec(工具规范):工具(函数、API 等)的结构化表示。围绕 FastMCP 2.0,ToolSpec 支持从函数、代码、MCP 或 FastMCP 工具相互转换,并可导出为函数、签名、代码、MCP 或 FastMCP 工具、函数调用 JSON Schema、字符串与 UKF。
Imitator(模仿器):基于模仿学习的智能体构建器。利用 KLBase 中的知识,通过弱监督创建并持续打磨特定领域的智能体。
2. 统一知识格式(UKF)架构¶
统一知识格式(UKF)是 AgentHeaven 的核心概念,提供了一种标准化的方式来表示和管理跨不同领域和应用的知识。UKF 架构设计为可扩展和适应性强,允许用户定义领域特定的知识表示,同时保持知识操作的一致接口。
统一知识格式(UKF)架构¶
在开发垂直领域应用时,应在领域专家的指导下首先定义对应领域的 UKF 变体(UKF Variants)。例如在数据库场景中,枚举、列、表与数据库模式都是重要的知识类型,因而都应被定义为 UKF 变体。
为便于使用,AgentHeaven 提供了一些基础的一级变体(如 KnowledgeUKFT、ExperienceUKFT、DocumentUKFT 等),并内置了若干二级变体(例如面向数据库的变体)继承自这些一级变体;同时也允许用户通过继承内置变体或其他自定义变体来定义自己的二级或三级变体。
随后,所有领域知识都可以被转换为这些变体的 UKF 实例,并按照 BaseUKF 协议支持全部相关操作。
BaseUKF 的底层处理对终端用户与应用开发者应当是“不可感知”的——他们只需关注对 UKF 实例的高层操作。
对贡献者而言,由于 BaseUKF 采用基于类型的适配器系统,你可以轻松实现适配器以修改 BaseUKF 的定义,或将 UKF 连接到你自己的后端。
具体来说,BaseUKF 模式中的每个字段都关联一个 UKF 类型(UKF Type)。若要将 BaseUKF 连接到自定义后端,需要为这些 UKF 类型实现适配器——例如把
UKFShortTextType映射为 SQL 数据库中的VARCHAR(255),或把UKFVectorType连接到向量数据库中的_vec。对于内置适配器,AgentHeaven 旨在提供统一实现,而不是为每个后端分别实现适配器。因此我们引入了另一层 Connector,通过第三方集成器连接各类后端。例如,SQLAlchemy Connector 连接多种 SQL 数据库,而 LlamaIndex Connector 连接多种向量数据库。
至于将原始的领域知识转换为 UKF 实例——这一过程高度依赖具体领域——AgentHeaven 倡导 Agents for Agents 的理念:我们为智能体构建知识库,同时也利用智能体来辅助构建它。具体而言,在下一节我们将介绍 Imitator(模仿器) 组件,我们认为它是实现智能体系统终身学习的一种通用机制。在我们的演示中,我们展示了如何借助 Imitator 与 AgentHeaven 的工具,在实际场景中快速搭建一个 UKF 抽取智能体。
3. 模仿器架构¶
从概念上,我们将通过智能体工作流解决的所有任务表述为一个 函数(Function)。当前,AgentHeaven 仅考虑既是记录级(record-wise,意指每条输入记录恰对应一条输出记录)又是确定性的函数。需要注意的是,这里的“函数”并不局限于代码中实现的实际函数,也可指代人工标注、LLM 调用或完整的智能体工作流。
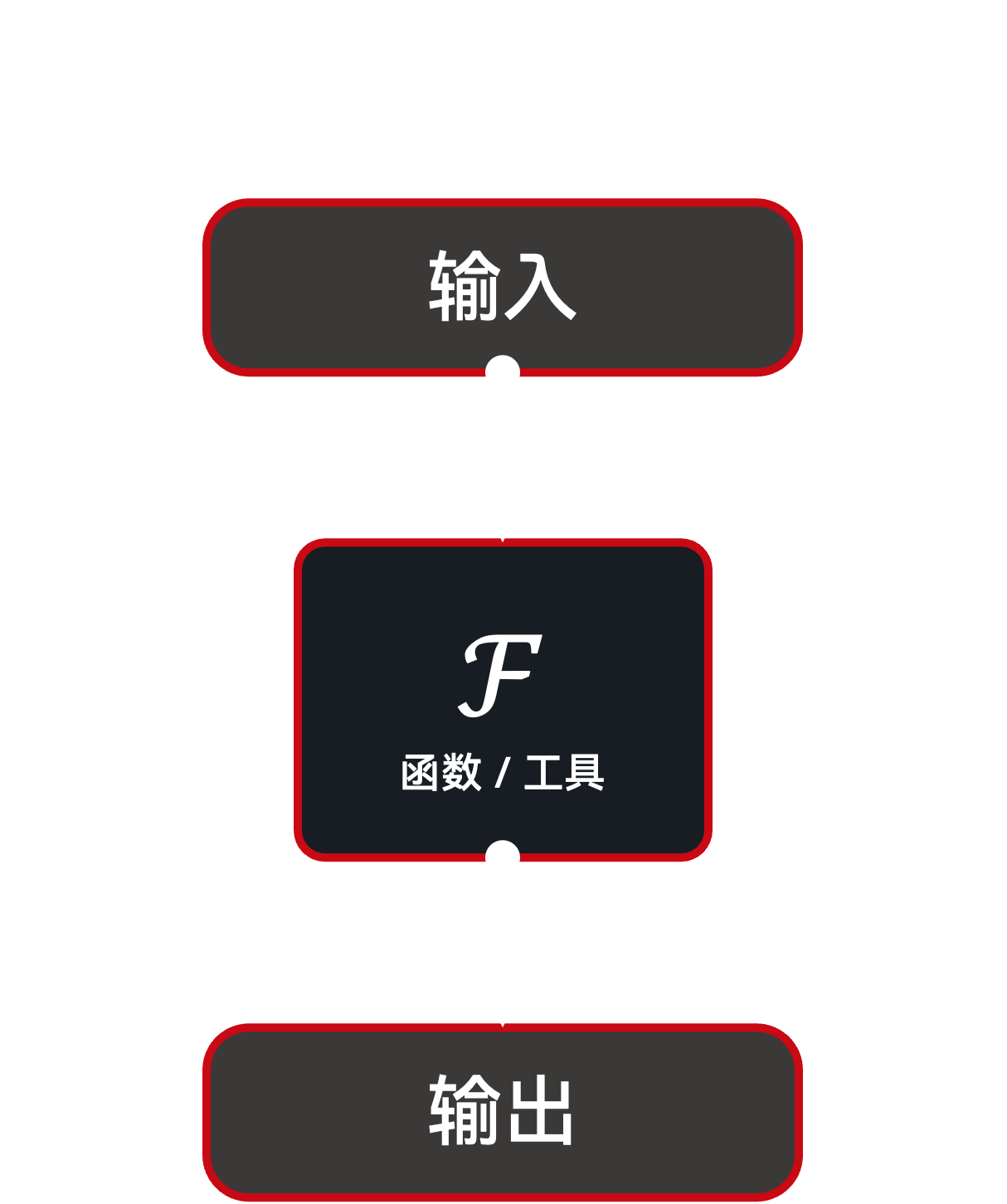
模仿器架构:函数¶
为实现终身学习,首先需要跟踪函数调用及其结果。这由 Cache(缓存) 组件(更具体地说是 CallbackCache)完成,它可以作为装饰器包装任意函数,从而创建一个 受监控函数(Monitored Function)。受监控函数在继续接收相同输入并产生相同输出的同时,还会向缓存发出 CacheEntry 实例,记录函数名、输入参数、输出结果、时间戳与其他元数据。随后,这些 CacheEntry 可被转换为 UKF 实例(例如 ExperienceUKFT),并被存入 KLBase(知识库) 进行长期管理。
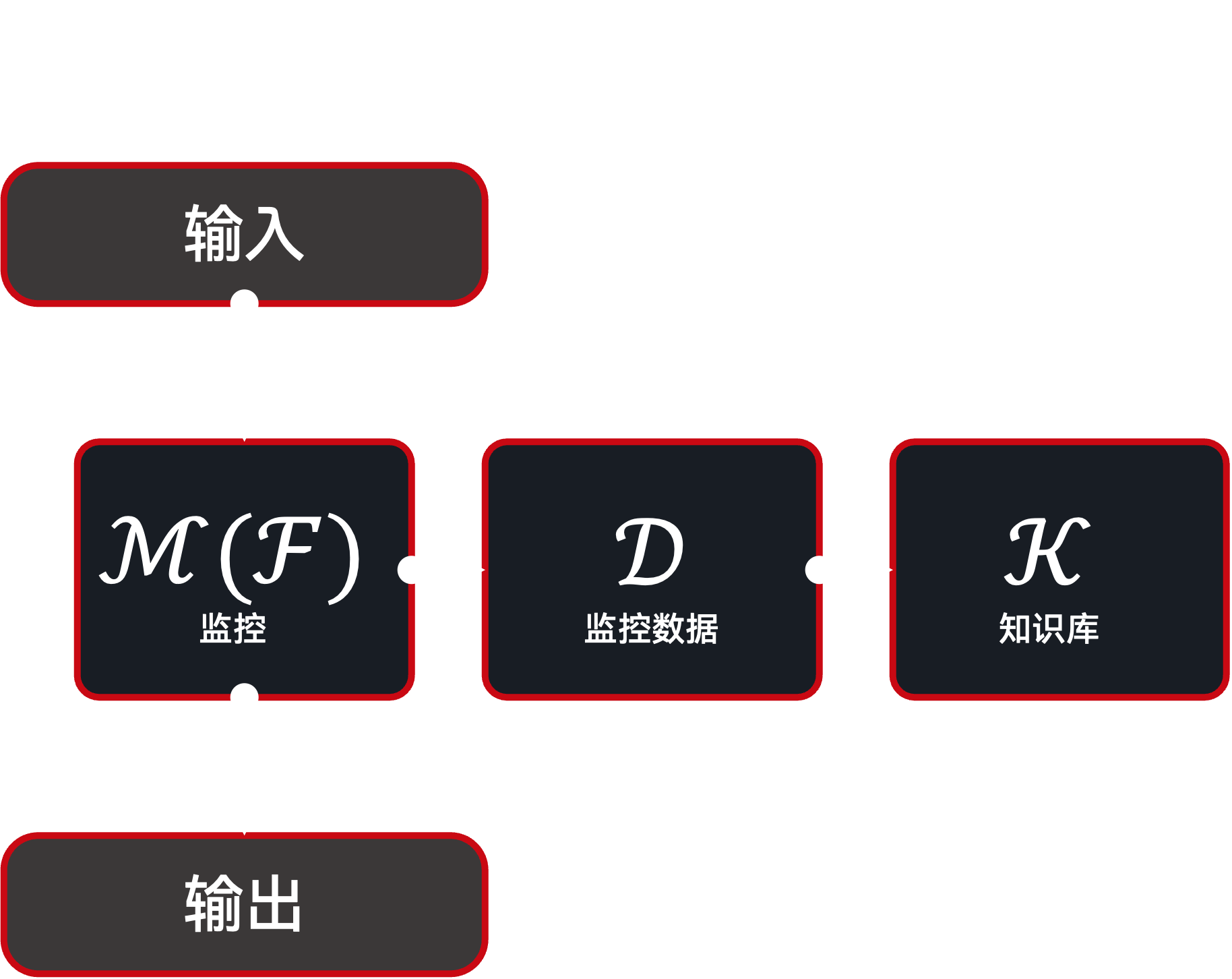
模仿器架构:受监控函数¶
此时,我们拥有一个包含函数经验(以及可能的其他知识)的 KLBase。下一步便是从 KLBase 中构建一个 仿函数(Mimic Function)。仿函数以黑盒形式模拟原始函数:在同样的输入基础上,结合 KLBase,产生与原始函数相似(甚至更优)的输出。
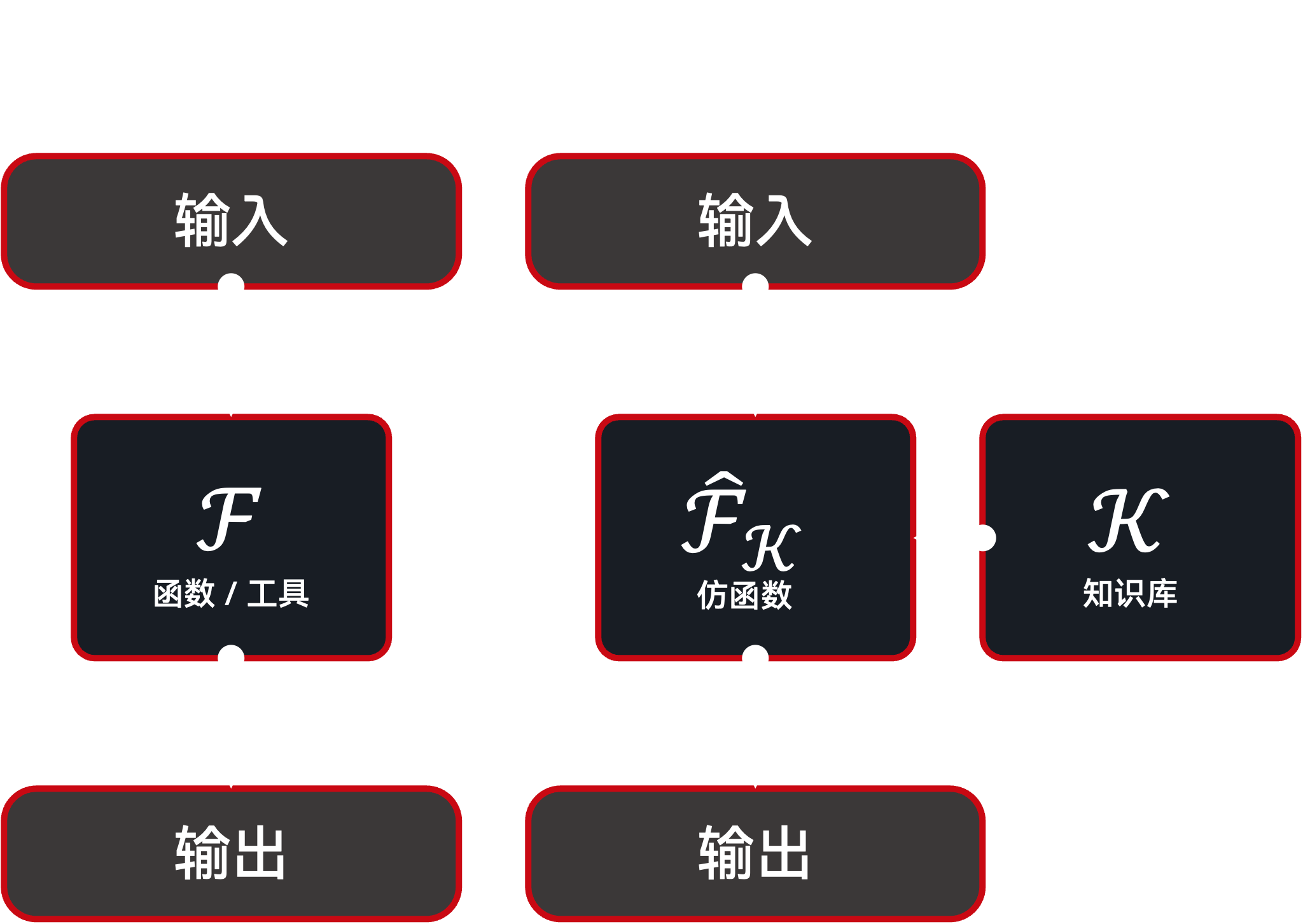
模仿器架构:仿函数¶
仿函数可以通过多种方式实现,例如基于提示工程的上下文学习(ICL)、微调、将 ExperienceUKFT 作为单元测试的代码生成,或基于历史输入/输出的精确/模糊匹配。随后,仿函数可以作为原始函数的即插即用替代品。
最后,我们可以将函数、监控器(Cache)与仿函数(或仿函数工厂)组装为一个 Imitator(模仿器)。模仿器与某个 KLBase 绑定,可按需监控任意函数,在后台安静地收集经验并把它们存入 KLBase。
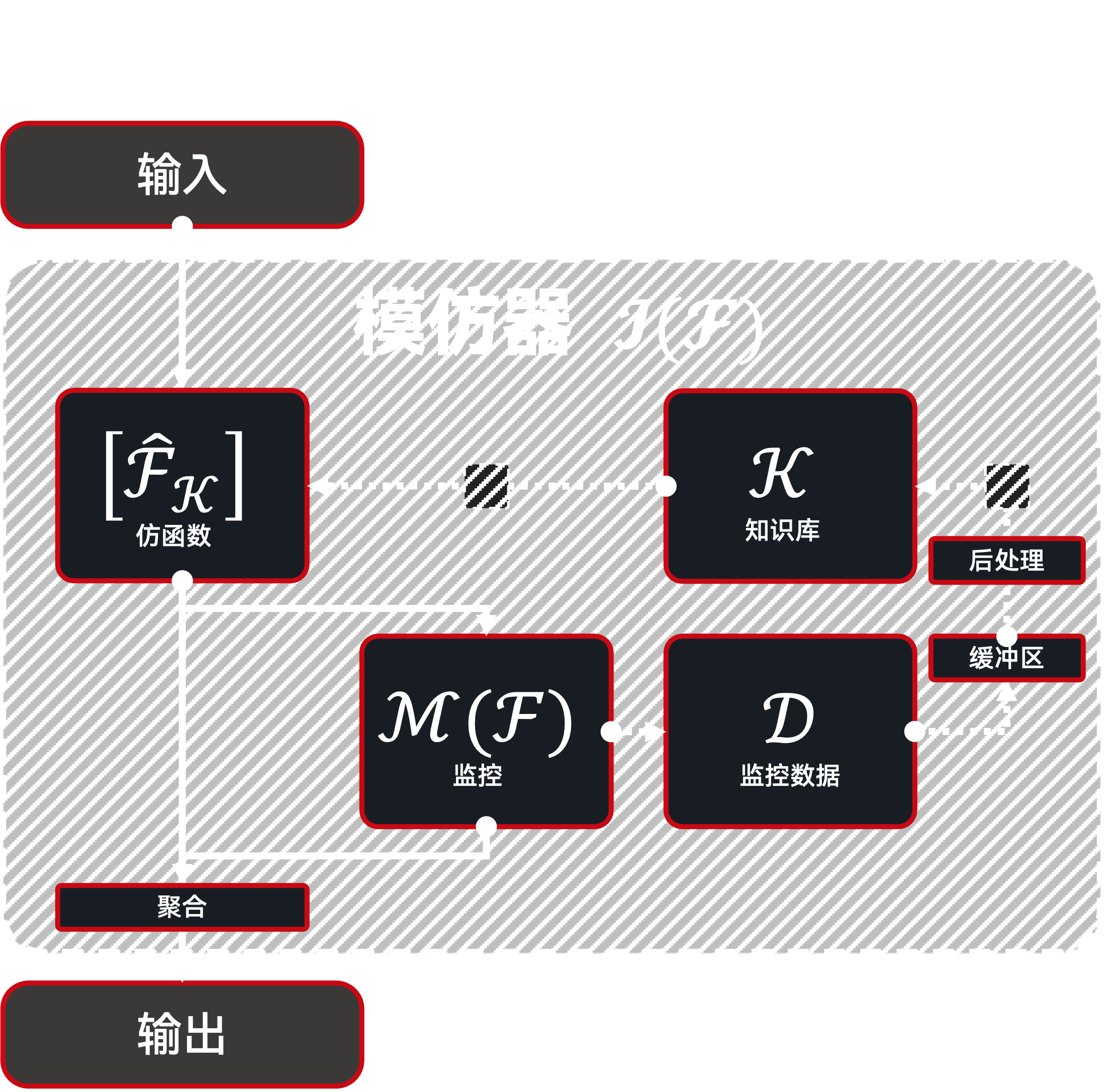
模仿器架构:完整工作流¶
在任意时刻,模仿器都可以基于 KLBase 构建一个仿函数。随后可以应用一个 聚合器(Aggregator),将原始函数与不同版本仿函数的输出进行组合,得到最终结果。
最终,这些聚合后的仿函数可以完全替代原始函数:要么通过引入来自 KLBase 的额外知识或从历史数据中学习而产生更优输出;要么以更低成本产生输出(例如以基于 LLM 的仿函数替代人工标注,甚至以基于代码生成的固定代码片段进一步加速)。
目前,AgentHeaven 仅内置了一种模仿器,其聚合器采用级联机制:按顺序依次尝试一系列仿函数,并返回第一个非空输出作为最终结果。仿函数基于 ICL 实现,会使用从 KLBase 检索到的历史经验来构建提示中的上下文示例。
其他聚合器与仿函数的实现将会在未来提供,敬请期待。
对开发者而言,你可以继承基础的 Imitator 类,自定义实现 Monitor、Mimic 与 Aggregator 组件以构建你自己的模仿器。
需要注意的是,在上述架构图的组件之间存在一些浅色阴影小方块,涉及在缓冲区中处理受监控数据,以及利用 KLBase 构建仿函数的过程。这些流程需要领域特定的逻辑,可能需要人工开发者介入。然而,这里同样可以应用 Agents for Agents 的思路:这些小方块可以被抽象为“函数”,并可以递归地通过模仿器来实现。
直观来看,凡是可以受益于自动化的任务,总会同时存在共性与差异性。共性(80% 的简单情形)可以由模仿器处理;而差异性(20% 的困难情形)则需要人工介入。若人工介入成本较高,它同样会是一个可以受益于自动化的任务,并再次体现出共性与差异性。通过递归地应用这一原则,我们可以逐步自动化越来越多的任务,在保留人类参与的同时尽量减少人力成本。就像自注意力是 Transformer 的基石一样,我们相信模仿器是智能体系统实现终身学习的基石。